

Advanced Clustering
Accessing Wizard
To open the clustering wizard and design clustering models:
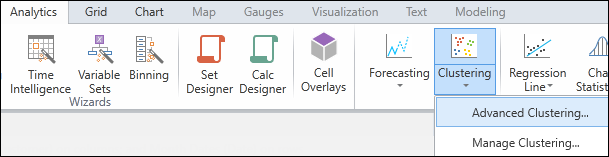
- Click Clustering icon in Data Discovery/Analytics ribbon.
- Select Advanced Clustering command.
Clustering Wizard Dialogs
The cluster wizard contains the following interactive dialogs.
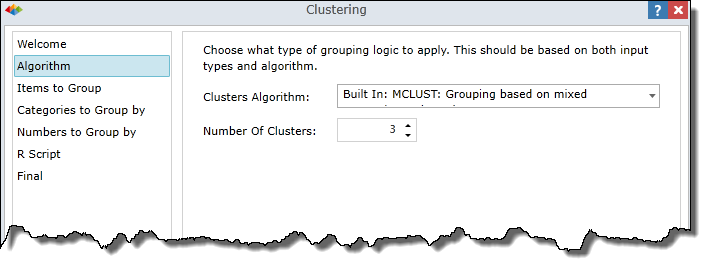
Algorithm
Choose a Clustering Algorithm
Choose the algorithm on which to base your clustering model.
- EMMD is a model-based clustering method that is based on a probability model calculated from the data.
- KMEANS defines clusters based on the minimum square distance FROM each data point in each cluster TO the mean of that cluster.
- MCLUST* is a model-based clustering method that is based on a probability model calculated from the data.
- PAM defines clusters based on the minimum distance FROM each data point in each cluster TO the mean of that cluster.
- KMODE* defines clusters based on the number of matching categories BETWEEN data points.
The table below shows which input types are required by each algorithm:
| Algorithm | Categories to Group by | Numbers to Group by |
| EMMD | YES | YES |
| KMEANS | YES | |
| MCLUST* | YES* | |
| PAM | YES | |
| KMODE* | YES |
* Require two or more input parameters.
Number of Clusters
Specify the number of clusters to be generated by your clustering model.
Items to Group
Choose the desired Dimension and Hierarchy.
- If you choose a user hierarchy
 , you also need to choose a Level.
, you also need to choose a Level. - If you choose an attribute hierarchy
 , the Level field does not appear.
, the Level field does not appear.
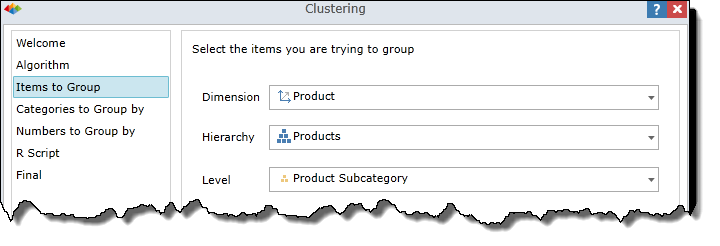
Categories to Group by
Specify one or more categories (attribute hierarchies) by which to group your data items into clusters. The six-pack icon indicates that the hierarchy is an attribute hierarchy, meaning it's a flat data structure containing a single data level.
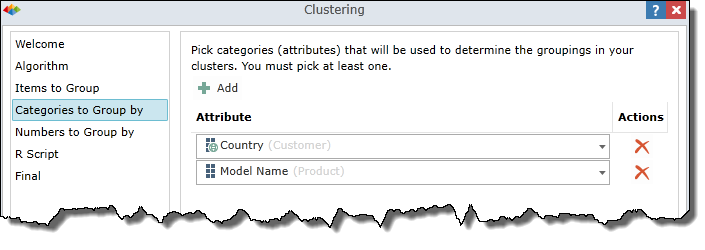
Numbers to Group by
Specify one or more numbers (measures) by which to group your data items into clusters.
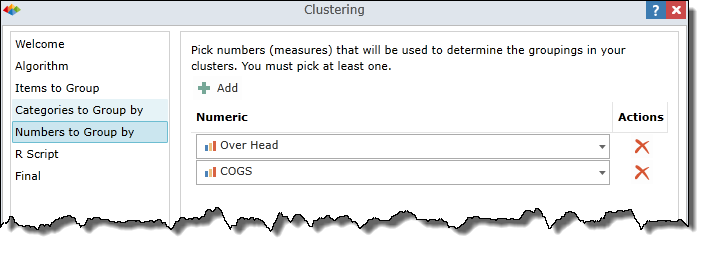
R Script
Automatic Mode
By default, the "Customize Script" box is unchecked and the wizard interactively generates an R Script based on your current wizard selections. If you make changes to your wizard selections, the R Script is instantly updated.
Manual Mode
If you check the "Customize Script" box, the R Script is disconnected from the clustering wizard. The R Script enters manual mode "as is" and will no longer be updated automatically. At this point, you may edit the R Script and the clustering model will be generated based on your custom R Script.
If you later uncheck the box, you return to Automatic Mode and the R Script will be instantly changed to match your current wizard selections. Your manual changes will be lost. If you wish to preserve your changes, be sure to create a duplicate copy of the clustering model or copy/paste your R Script into an external editor such as Notepad.
R Script Parameters
The following parameters appear in the R Script:
- Input - Table of values (based on your wizard selections).
- Output - Vector of integers containing each item's cluster number. For example, an output of 1, 3, 2, 3 indicates that the first item is in cluster 1, the second is in cluster 3, the third is in cluster 2, and the fourth is in cluster 3.
Final
In the Final dialog you select output options and then click OK to generate a clustering model.
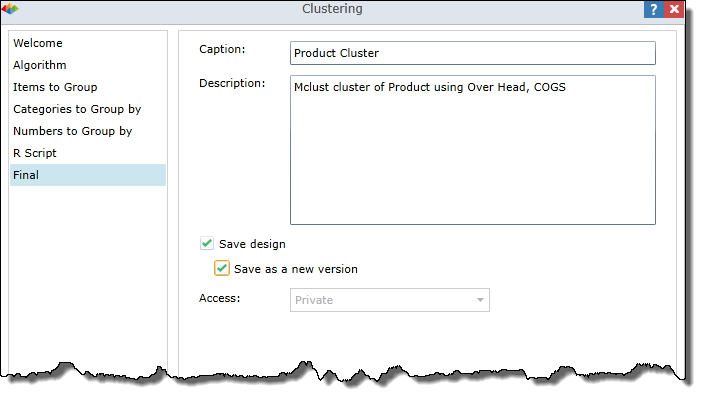
Caption - This name is used to create the clustering model, as well as the Custom Sets and Customer Members. A default name is supplied, based on your current wizard selections. The name can be used "as is", edited or replaced
Description - A default description is supplied, based on your current wizard selections. The description can be used "as is", edited or replaced
Save design - Check this box if you wish to save the clustering model for future usage. The model can be used with any report that is based on the same data model.
Save as a new version - By default, this box is unchecked and the system prevents you from saving the clustering model with an existing name. If checked, you can save with an existing name and the system will create an additional version of the existing model.
Access - Select Private or Public to specify security rights for accessing your clustering model.
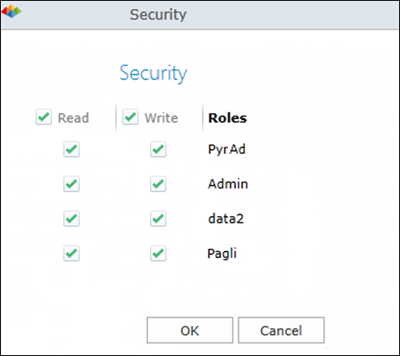
Access Rights
Before the clustering model is saved, the Security dialog appears. Use this dialog to set access rights for your clustering model and the output (Custom Sets and Customer Members).
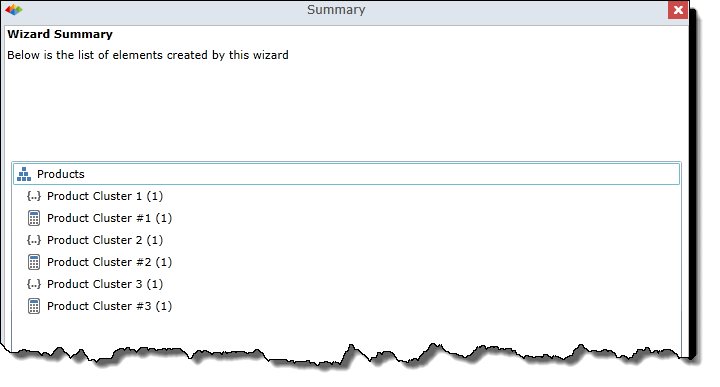
Wizard Summary
In the example below, three set/member pairs have been created (one for each cluster).
See Also
Home |
Table of Contents |
Index |
User Community
Pyramid Analytics © 2011-2022